
I am Xuanyu Zhang (张轩宇), a Ph.D. Student at the School of Computer Science, Peking University, advised by Prof. Jian Zhang. Previously, I received my B.Eng degree from School of Electrical and Information Engineering, Tianjin University, advised by Prof. Jianjun Lei, Pengfei Zhu, and Bo Peng. Please feel free to reach out via email (xuanyuzhang21@stu.pku.edu.cn).
My recent research interests focus on MLLM, Unified Model, and Visual Generation Agent. I have published 10+ CCF-A papers (as the first/co-first author) with a total Google Scholar citations of 1600+ at top-tier venues including ICML, ECCV, CVPR, NeurIPS, ICLR, AAAI, ACM MM and IJCV, with works spanning united visual understanding and generation, Image or video quality understanding, AIGC forgery localization, multi-agent frameworks, and robust watermarking/steganography for copyright protection. For more details on my publications, please visit my profiles on Google Scholar.
🔥 News
- 2026.05: 🎉🎉 One paper is accepted at ICML 2026.
- 2026.05: 🎉🎉 One paper is accepted at IJCV.
- 2026.05: 🎉🎉 One paper is accepted at ECCV 2026.
- 2026.02: 🎉🎉 Two papers are accepted at CVPR 2026.
- 2026.01: 🎉🎉 Two papers are accepted at ICLR 2026.
- 2025.11: 🎉🎉 One paper is accepted as AAAI 2026 Oral.
💻 Internships
Tencent Hunyuan · Qingyun Program · 2026.04 - present
- Research Focus: Unified model HY-Image-3.5
- World-grounded synthesis agents — enabling models to invoke external tools (e.g., search engines) for image generation
- Efficient agentic RL algorithms for unified generation and understanding
ByteDance · Jin Dou Yun Talent Program · 2025.04 - 2026.03 · Mentored by Shijie Zhao
- Research Focus: Reward models and reinforcement learning for generation
- Visual quality assessment LLMs: VQ-Insight (AAAI 2026 Oral), RALI (ICLR 2026 Oral)
- Video quality enhancement LLMs: AdcVSR (ICLR 2026), OARS (ECCV 2026)
- Quality enhancement agent: VQ-Jarvis (IJCV)
📝 Selected Publications
(# denotes equal contribution)
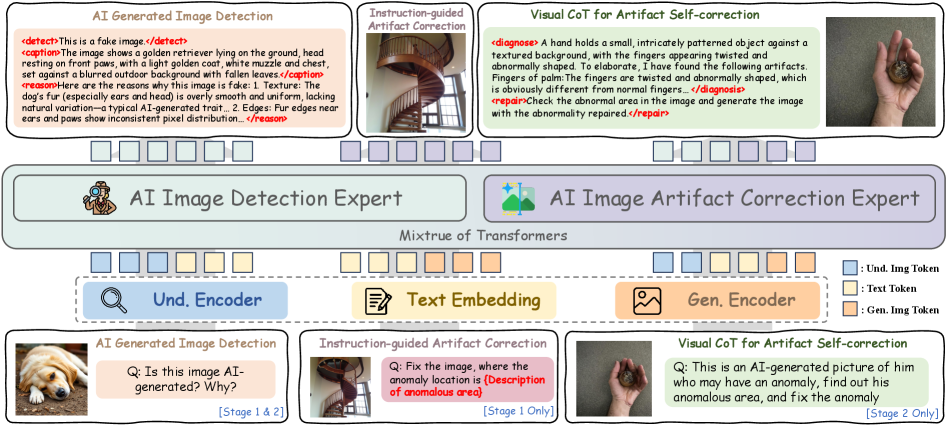
GenShield: Unified Detection and Artifact Correction for AI-Generated Images
Zhipei Xu#, Xuanyu Zhang#, Youmin Xu#, Qing Huang, Shen Chen, Taiping Yao, Shouhong Ding, Jian Zhang
ICML 2026
Paper | Code
We propose GenShield, a unified autoregressive framework that jointly performs explainable AI-generated image detection and controllable artifact correction in a closed loop from diagnosis to restoration, built on a Mixture-of-Transformers architecture with a Visual Chain-of-Thought curriculum learning strategy.

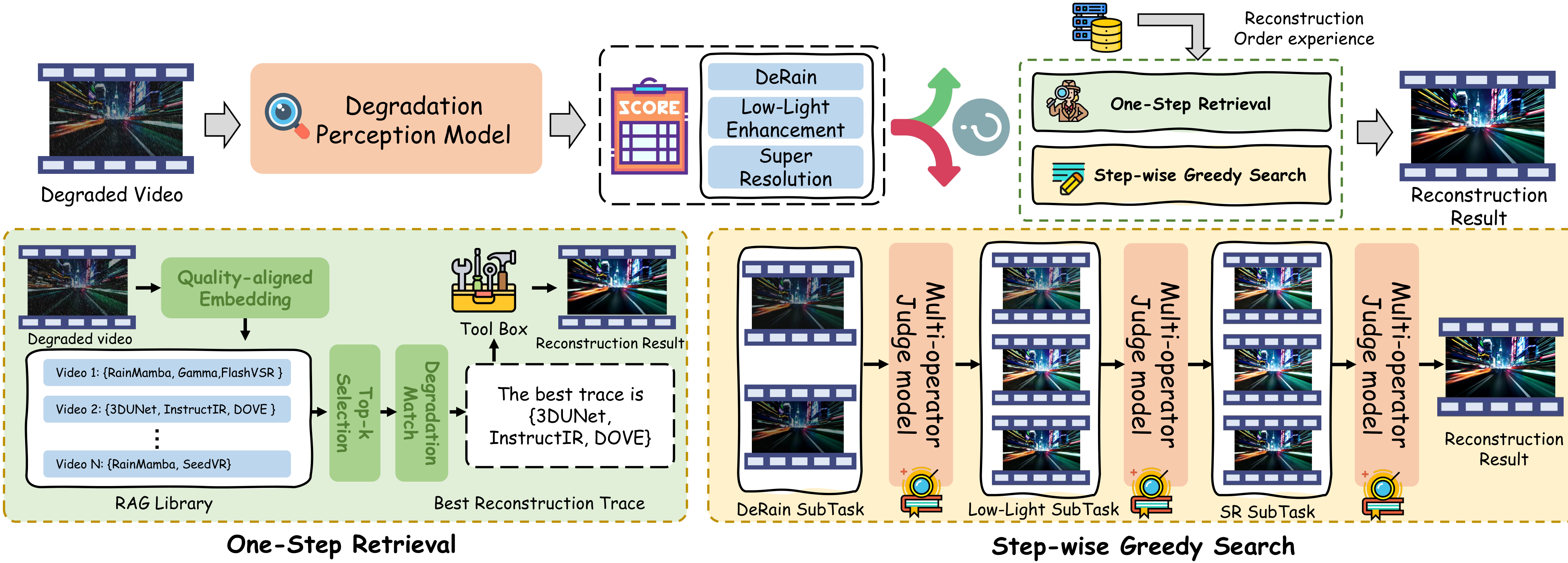
VQ-Jarvis: Retrieval-Augmented Video Restoration Agent with Sharp Vision and Fast Thought
Xuanyu Zhang, Weiqi Li, Qunliang Xing, Jingfen Xie, Bin Chen, Junlin Li, Li Zhang, Jian Zhang, Shijie Zhao
IJCV
Paper
We propose VQ-Jarvis, a retrieval-augmented, all-in-one intelligent video restoration agent. VQ-Jarvis features sharp vision through a large-scale paired enhancement dataset and GRPO-aligned perception models, and fast thought via a hierarchical scheduling strategy that retrieves optimal restoration trajectories from a RAG library or performs greedy search for complex cases.
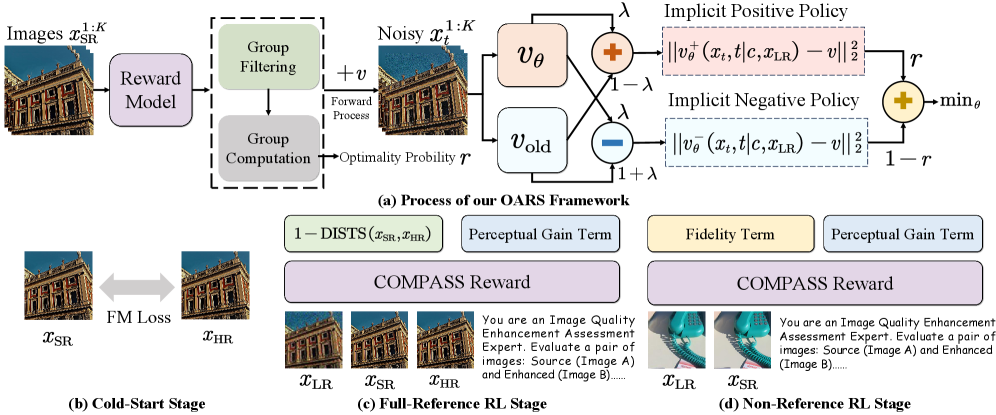
OARS: Process-Aware Online Alignment for Generative Real-World Image Super-Resolution
Shijie Zhao#, Xuanyu Zhang#, Bin Chen, Weiqi Li, Qunliang Xing, Kexin Zhang, Yan Wang, Junlin Li, Li Zhang, Jian Zhang, Tianfan Xue
ECCV 2026
Paper
We propose OARS, a process-aware online alignment framework for generative real-world image super-resolution, built on COMPASS, a MLLM-based reward model that evaluates the LR-to-SR transition by jointly modeling fidelity preservation and perceptual gain. OARS performs progressive online alignment from cold-start flow matching to full-reference and reference-free RL.
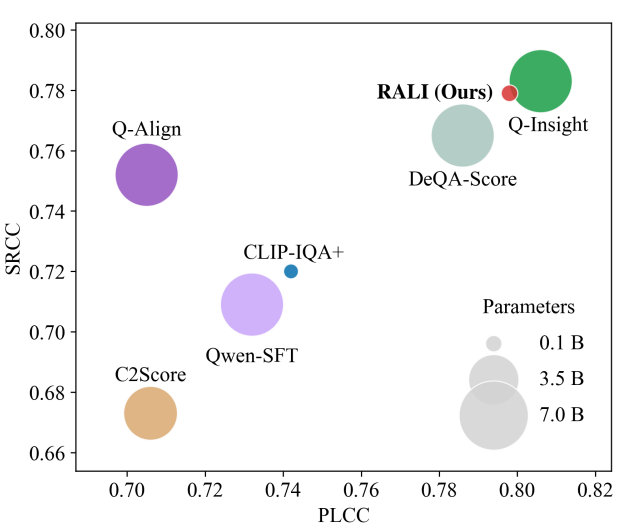
Reasoning as Representation: Rethinking Visual Reinforcement Learning in Image Quality Assessment
Shijie Zhao#, Xuanyu Zhang#, Weiqi Li, Junlin Li, Li Zhang, Tianfan Xue, Jian Zhang
ICLR 2026 Oral
Paper | Code 
We revisit the reasoning mechanism in MLLM-based IQA model and propose a CLIP-based lightweight image scorer RALI. We verifies that through RL training, MLLMs leverage their reasoning capability to convert redundant visual representations into compact, cross-domain aligned text representations. This conversion is the source of the generalization exhibited by these reasoning-based IQA models. RALI uses only about 4% of Q-Insight’s parameters and inference time, while achieving comparable accuracy.
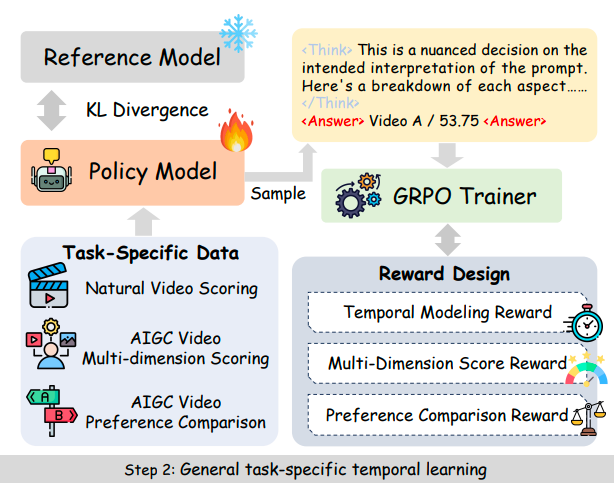
Xuanyu Zhang, Weiqi Li, Shijie Zhao, Junlin Li, Li Zhang, Jian Zhang
AAAI 2026 Oral
Paper | Code
We propose VQ-Insight, a novel reasoning-style VLM framework for AIGC video quality assessment. Our approach features: (1) a progressive video quality learning scheme; (2) the design of multi-dimension scoring rewards, preference comparison rewards, and temporal modeling rewards.

Zhipei Xu#, Xuanyu Zhang#, Runyi Li, Zecheng Tang, Qing Huang, Jian Zhang
ICLR 2025
Project | Code
We propose the explainable IFDL task and design FakeShield, a multi-modal framework capable of evaluating image authenticity, generating tampered region masks, and providing a judgment basis based on pixel-level and image-level tampering clues.

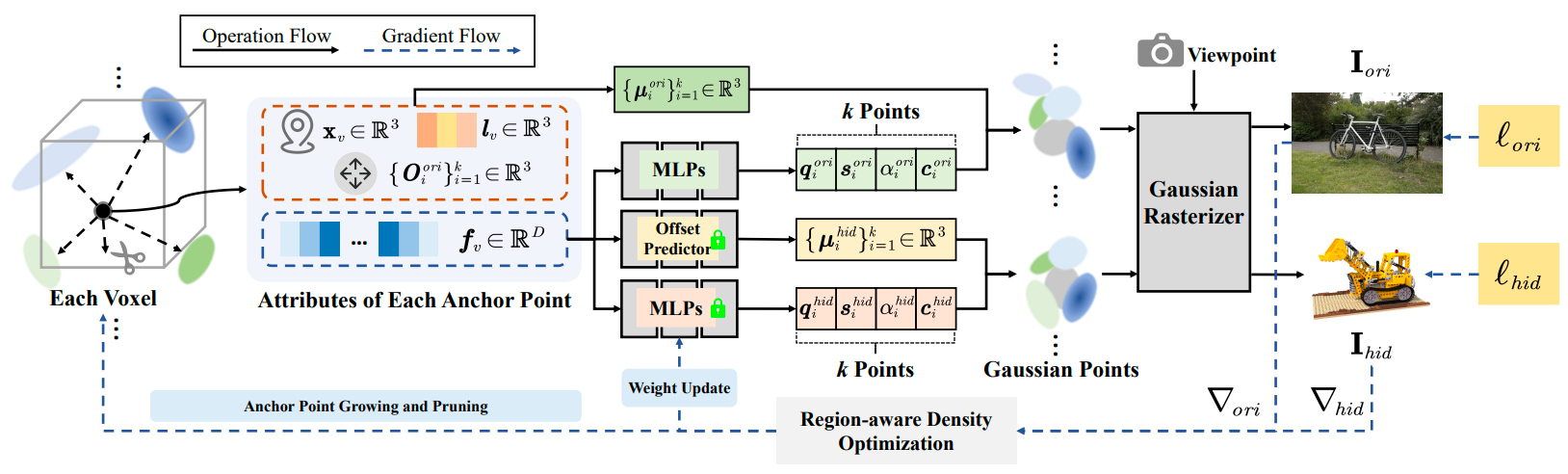
SecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Xuanyu Zhang, Jiarui Meng, Zhipei Xu, Shuzhou Yang, Yanmin Wu, Ronggang Wang, Jian Zhang
ICLR 2025
Paper | Code
We propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS’s anchor point design and neural decoding.
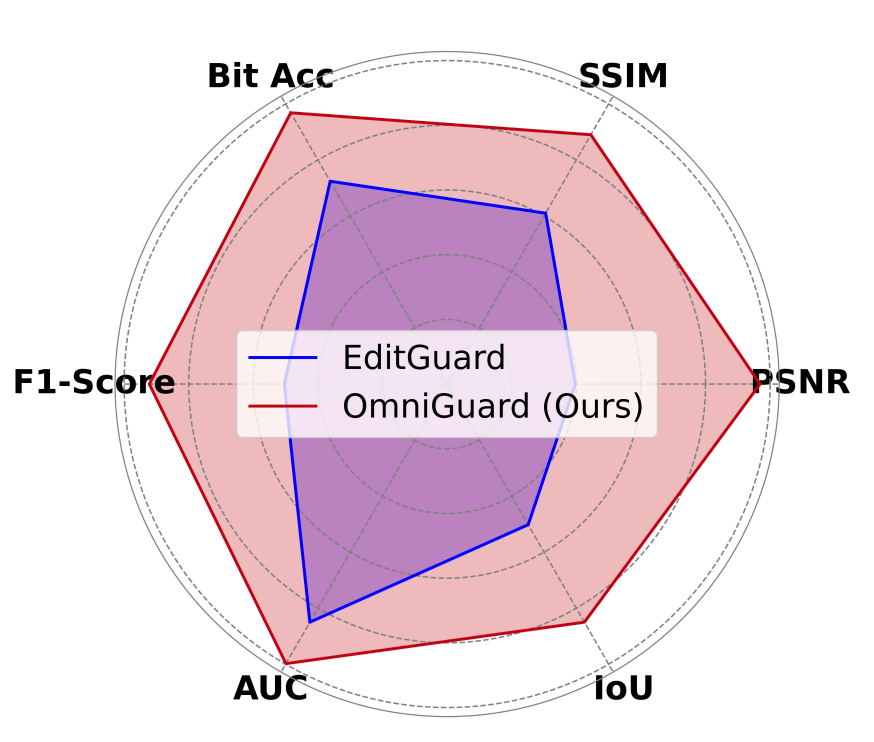
OmniGuard: Hybrid Manipulation Localization via Augmented Versatile Deep Image Watermarking
Xuanyu Zhang, Zecheng Tang, Zhipei Xu, Runyi Li, Youmin Xu, Bin Chen, Feng Gao, Jian Zhang
CVPR 2025
Paper | Code
We propose OmniGuard, a novel augmented versatile watermarking approach that integrates proactive embedding with passive, blind extraction for robust copyright protection and tamper localization.

GS-Hider: Hiding Messages into 3D Gaussian Splatting
Xuanyu Zhang, Jiarui Meng, Runyi Li, Zhipei Xu, Yongbing Zhang, Jian Zhang
NeurIPS 2024
Paper | Code | Project
We propose the first 3DGS steganography framework GS-Hider, which can hide an entire 3D scene or an image into the original 3D scene and accurately decode it from 3D Gaussians.

EditGuard: Versatile Image Watermarking for Tamper Localization and Copyright Protection
Xuanyu Zhang, Runyi Li, Jiwen Yu, Youmin Xu, Weiqi Li, Jian Zhang
CVPR 2024
Paper | Code 
We propose a versatile deep forensic watermark for AIGC editing methods, such as stable diffusion inpaint, controlnet, SDXL and etc.
🎖 Honors and Awards
- 2023 - 2025 Outstanding Student Award at Peking University
- 2024.10 National Scholarship for Doctoral Students
- 2022.10 National Scholarship for Undergraduate Students
📖 Educations
- 2022.09 - 2027.06 (expected), Ph.D., Computer Science, Peking University
- 2018.09 - 2022.06, B.Eng, Computer Science (Second Degree), Tianjin University
- 2018.09 - 2022.06, B.Eng, Communication Engineering, Tianjin University