|
Xuanyu Zhang (张轩宇) I am a Phd student at Peking University, VILLA, supervised by Prof. Jian Zhang. Previously, I received my B.Eng degree from Tianjin University in 2022. My recent research interests include Computer Vision, MLLM, and AIGC Security. |

|
Selected Publications |
|
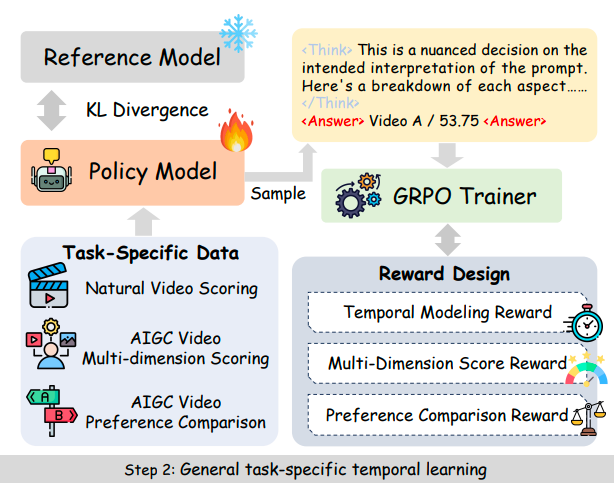
VQ-Insight: Teaching VLMs for AI-Generated Video Quality Understanding via Progressive Visual Reinforcement Learning
Xuanyu Zhang, Weiqi Li, Shijie Zhao, Junlin Li, Li Zhang Jian Zhang AAAI Conference on Artificial Intelligence, 2026 project page / arXiv We propose VQ-Insight, a novel reasoning-style VLM framework for AIGC video quality assessment. Our approach features: (1) a progressive video quality learning scheme; (2) the design of multi-dimension scoring rewards, preference comparison rewards, and temporal modeling rewards. |
|
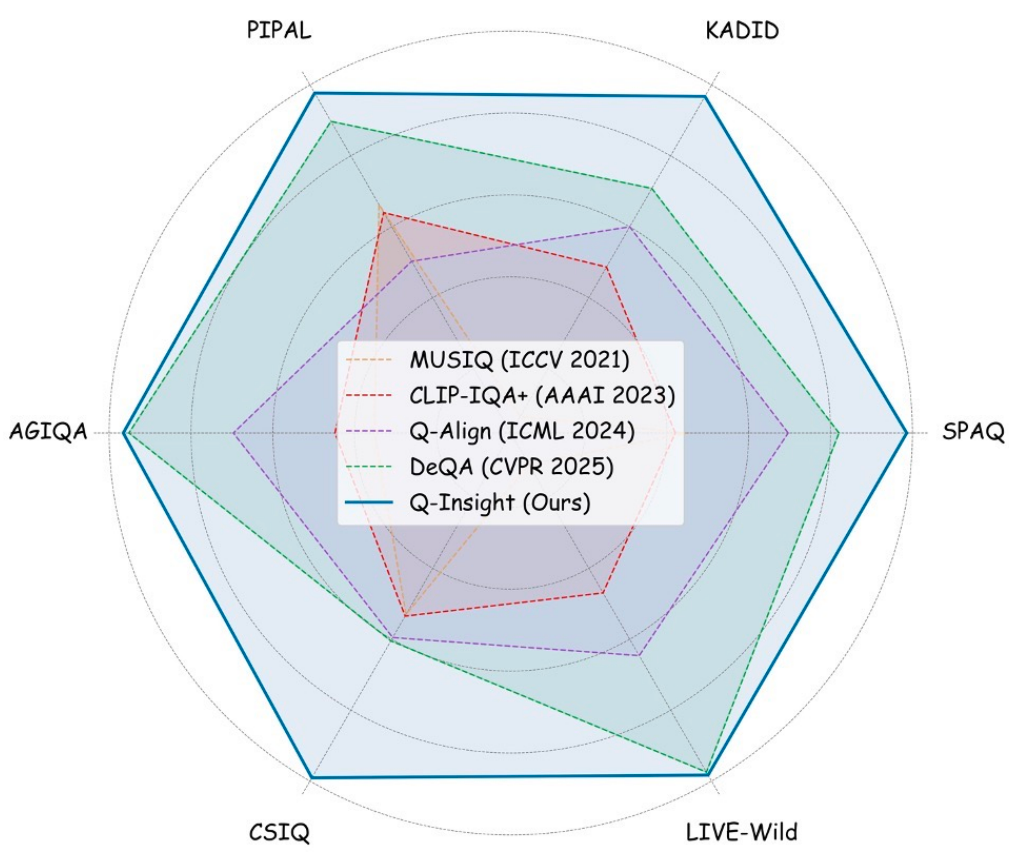
Q-Insight: Understanding Image Quality via Visual Reinforcement Learning
Weiqi Li, Xuanyu Zhang, Shijie Zhao, Yabin Zhang, Junlin Li, Li Zhang Jian Zhang The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025 project page / arXiv We propose Q-Insight, a reinforcement learning-based model built upon group relative policy optimization (GRPO), which demonstrates strong visual reasoning capability for image quality understanding while requiring only a limited amount of rating scores and degradation labels. |

|
FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models
Zhipei Xu*, Xuanyu Zhang*, Runyi Li, Zecheng Tang, Qing Huang, Jian Zhang International Conference on Learning Representations (ICLR), 2025 project page / arXiv We propose the explainable IFDL task and design FakeShield, a multi-modal framework capable of evaluating image authenticity, generating tampered region masks, and providing a judgment basis based on pixel-level and image-level tampering clues. |
|
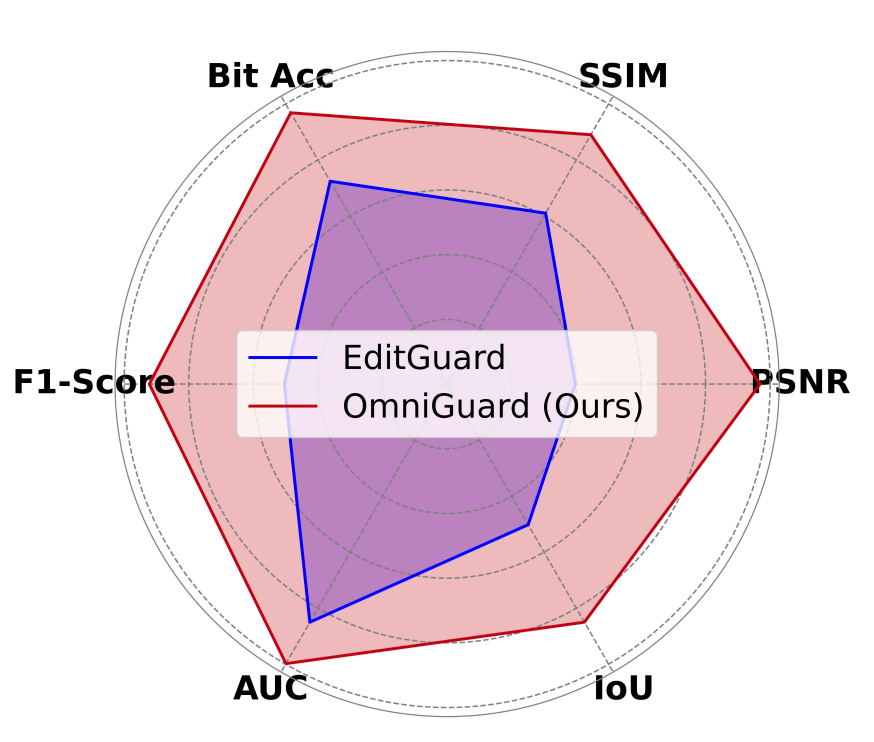
OmniGuard: Hybrid Manipulation Localization via Augmented Versatile Deep Image Watermarking
Xuanyu Zhang, Zecheng Tang, Zhipei Xu, Runyi Li, Youmin Xu, Bin Chen, Feng Gao, Jian Zhang IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2025 project page / arXiv We propose OmniGuard, a novel augmented versatile watermarking approach that integrates proactive embedding with passive, blind extraction for robust copyright protection and tamper localization. |
|
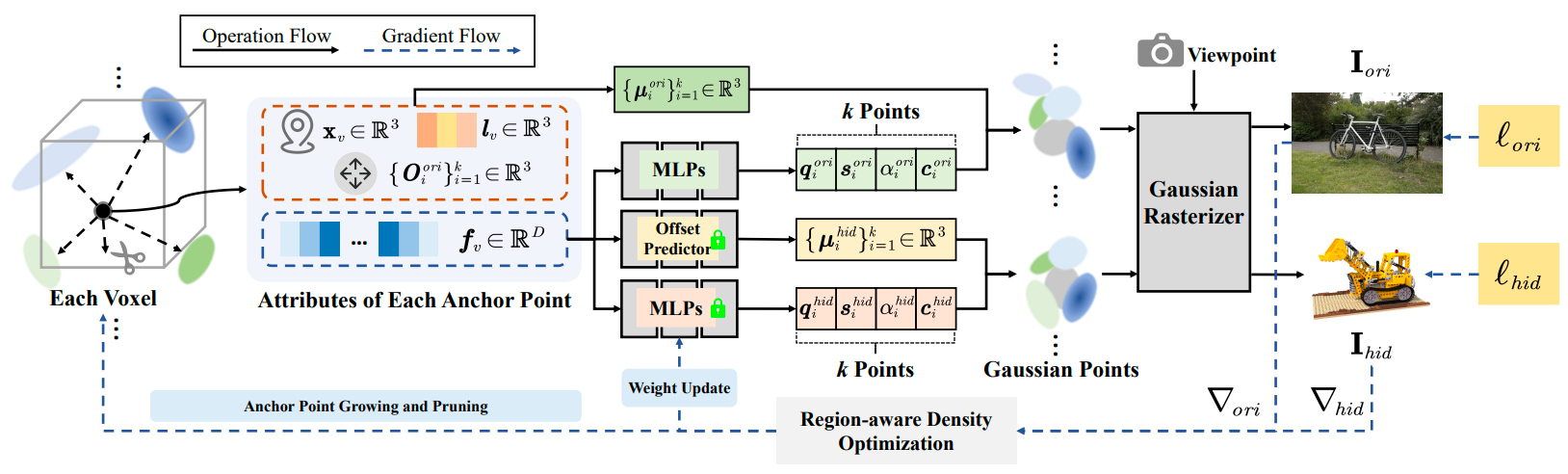
SecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Xuanyu Zhang, Jiarui Meng, Zhipei Xu, Shuzhou Yang, Yanmin Wu, Ronggang Wang, Jian Zhang International Conference on Learning Representations (ICLR), 2025 project page / arXiv We propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS's anchor point design and neural decoding. |
 
|
GS-Hider: Hiding Messages into 3D Gaussian Splatting
Xuanyu Zhang, Jiarui Meng, Runyi Li, Zhipei Xu, Yongbing Zhang, Jian Zhang The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024 project page / arXiv We propose the first 3DGS steganography framework GS-Hider, which can hide an entire 3D scene or an image into the original 3D scene and accurately decode it from 3D Gaussians. |

|
V2A-Mark: Versatile Deep Visual-Audio Watermarking for Manipulation Localization and Copyright Protection
Xuanyu Zhang, Youmin Xu, Runyi Li, Jiwen Yu, Weiqi Li, Zhipei Xu, Jian Zhang ACM Multimedia, 2024 arXiv We propose a versatile deep forensic watermark against AIGC editing methods for video and audio. |
 
|
EditGuard: Versatile Image Watermarking for Tamper Localization and Copyright Protection
Xuanyu Zhang, Runyi Li, Jiwen Yu, Youmin Xu, Weiqi Li, Jian Zhang IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 project page / video / arXiv We propose a versatile deep forensic watermark for AIGC editing methods, such as stable diffusion inpaint, controlnet, SDXL and etc. |
 
|
CRoSS: Diffusion Model Makes Controllable, Robust and Secure Image Steganography
Jiwen Yu, Xuanyu Zhang, Youmin Xu, Jian Zhang The Thirty-seventh Annual Conference on Neural Information Processing Systems (NeurIPS), 2023 code / arXiv We propose a novel diffusion-based image steganography framework named Controllable, Robust, and Secure Image Steganography (CRoSS). |
|
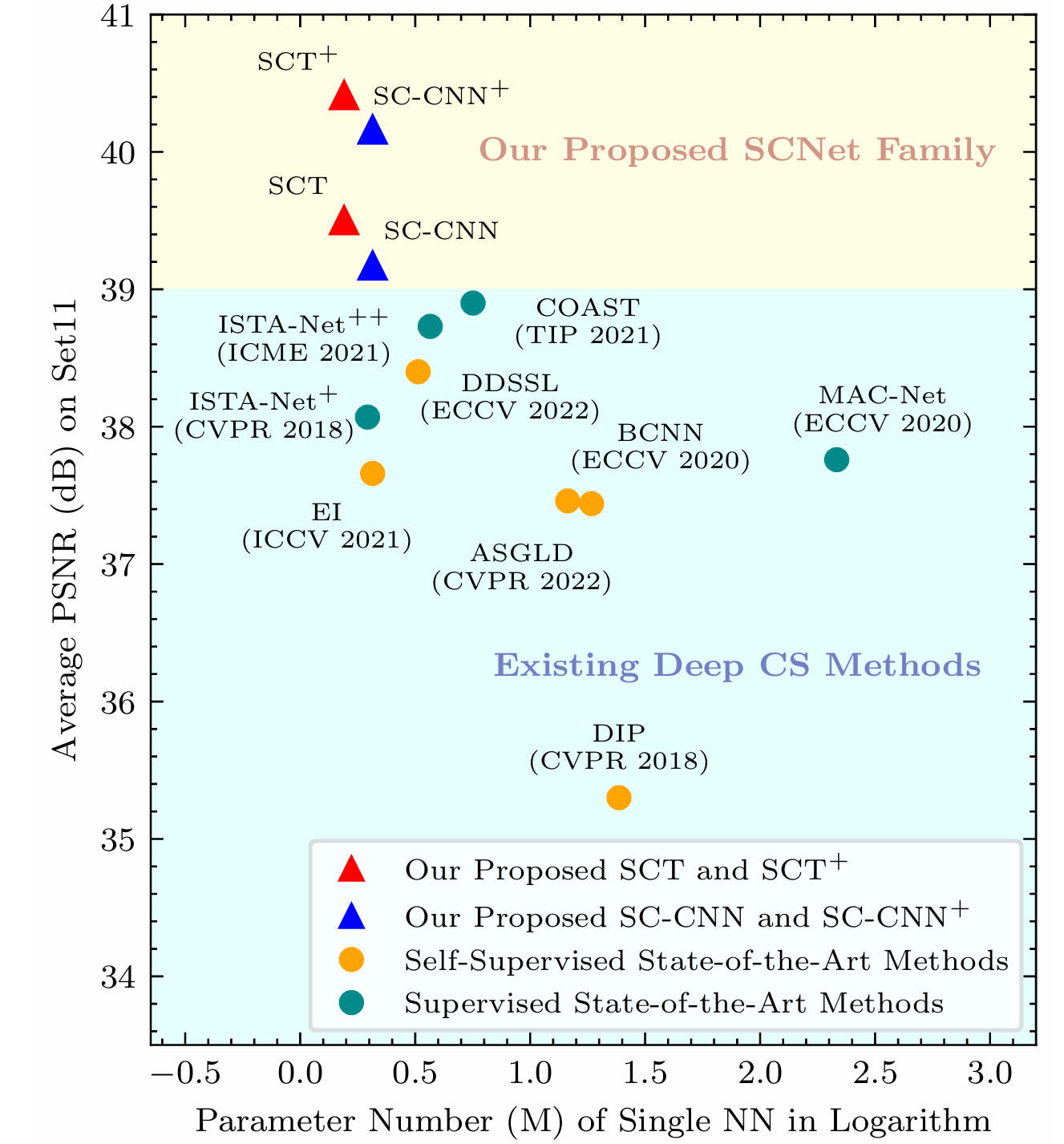
Self-Supervised Scalable Deep Compressed Sensing
Bin Chen, Xuanyu Zhang, Shuai Liu, Yongbing Zhang, Jian Zhang International Journal of Computer Vision, 2024 arXiv We propose a novel Self-supervised sCalable deep CS method, comprising a Learning scheme called SCL and a family of Networks named SCNet, which does not require GT and can handle arbitrary sampling ratios and matrices once trained on a partial measurement set. |
 
|
DiffLLE: Diffusion-guided Domain Calibration for Unsupervised Low-light Image Enhancement
Shuzhou Yang*, Xuanyu Zhang*, Yinhuai Wang, Jiwen Yu Yuhan Wang Jian Zhang International Journal of Computer Vision, 2024 arXiv We propose a novel diffusion-based low-light enhancement framework DiffLLE, which bridges the gap between real scenes and training data by diffusion model prior. |

|
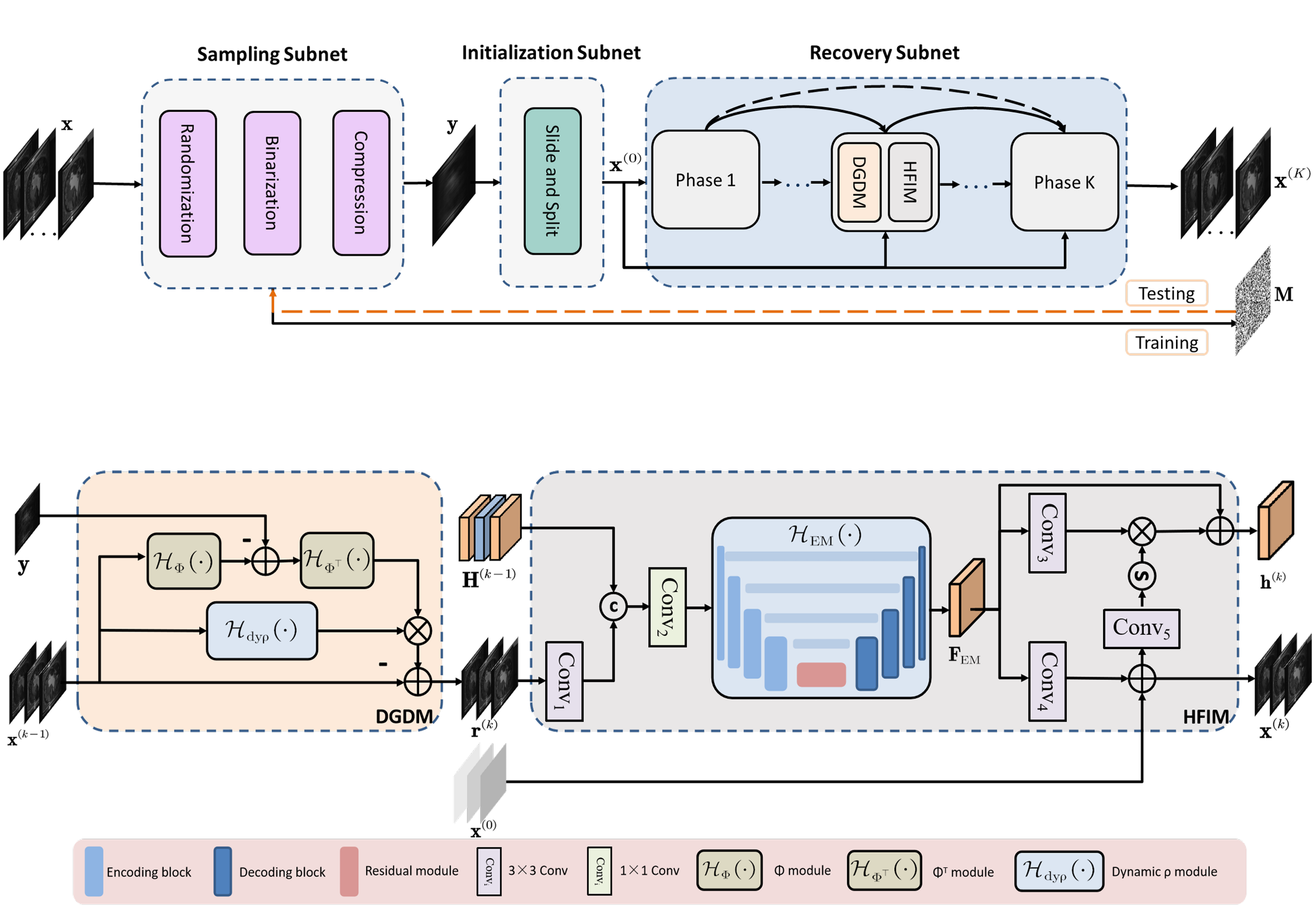
Progressive Content-aware Coded Hyperspectral Compressive Imaging
Xuanyu Zhang, Bin Chen, Wenzhen Zou, Shuai Liu, Yongbing Zhang, Ruiqin Xiong, Jian Zhang IEEE Transactions on Circuits and Systems for Video Technology, 2024 code / arXiv We propose a novel Progressive Content-Aware CASSI framework, dubbed PCA-CASSI, which captures HSIs with multiple optimized content-aware coded apertures and fuses all the snapshots for reconstruction progressively. |
|
HerosNet: Hyperspectral Explicable Reconstruction and Optimal Sampling
Deep Network for Snapshot Compressive Imaging
Xuanyu Zhang, Yongbing Zhang, Ruiqin Xiong, Qilin Sun, Jian Zhang IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 code / arXiv We propose a novel Hyperspectral Explicable Reconstruction and Optimal Sampling deep Network for SCI, dubbed HerosNet, which includes several phases un der the ISTA-unfolding framework. |
Academic Service and Awards |


|
|